키워드가 아닌 ‘의미’를 검색하는 시대, 벡터 데이터베이스 Qdrant는 무엇인가?
최근 AI 기술이 일상 속에 깊숙이 들어오면서 단순한 키워드 검색만으로는 사용자의 의도를 정확히 파악하기 어려워졌습니다. 사람의 언어나 이미지, 음악과 같은 복잡한 데이터는 단어 하나로 설명하기엔 너무나도 방대합니다. 그래서 지금 필요한 건 ‘단어’가 아닌 ‘의미’로 검색하는 방식입니다. 그리고 바로 이때 필요한 것이 ‘벡터 데이터베이스’입니다.
이 글에서는 벡터 데이터베이스의 기본 개념부터 시작해, 대표적인 벡터 검색 엔진인 Qdrant가 어떤 문제를 해결해주고 어떤 구조로 동작하는지, 그리고 어떤 방식으로 도입할 수 있는지까지 전반적으로 알아보겠습니다.

벡터 데이터베이스란 무엇인가?
기존 관계형 데이터베이스(RDB)는 데이터를 테이블 형태로 저장하고, 행과 열에 따라 조건을 걸어 조회하는 방식입니다. 예를 들어 이름이 "홍길동"인 사람을 찾는 쿼리는 아주 직관적입니다. 하지만 이미지나 문장의 유사도를 기준으로 비슷한 데이터를 찾고자 할 땐 이 방식이 매우 제한적입니다.
이때 필요한 것이 벡터 데이터베이스입니다. 벡터 DB는 데이터를 고차원 수치로 표현한 벡터(embedding)를 저장하고, 입력된 벡터와 가장 유사한 벡터를 찾아주는 역할을 합니다. 자연어 처리, 이미지 검색, 추천 시스템에서 이 방식이 특히 빛을 발합니다.
예를 들어 사용자가 어떤 이미지를 업로드하면, 시스템은 해당 이미지를 벡터로 변환하고, 기존 이미지 벡터들과 비교해 가장 유사한 결과를 반환합니다. 이 모든 과정은 숫자 공간 내 거리 계산을 통해 이루어집니다.
Qdrant란 무엇인가?
Qdrant는 벡터 유사도 검색을 위한 검색 엔진입니다. 고차원 벡터 데이터를 저장하고 검색하며 관리할 수 있는 API 기반의 서비스로, 실시간으로 벡터 유사도 검색이 가능한 프로덕션 레벨의 솔루션입니다.
특히 Qdrant는 각 벡터에 부가 정보를 담을 수 있는 ‘Payload’ 기능을 지원합니다. 이로써 단순한 유사도 검색을 넘어, 유의미한 필터링과 메타데이터 기반의 조건 검색까지 가능합니다.
Qdrant는 Python 클라이언트를 통해 손쉽게 시작할 수 있으며, Docker 이미지로 로컬에 실행하거나 Qdrant Cloud에서 무료로 체험해볼 수 있습니다.
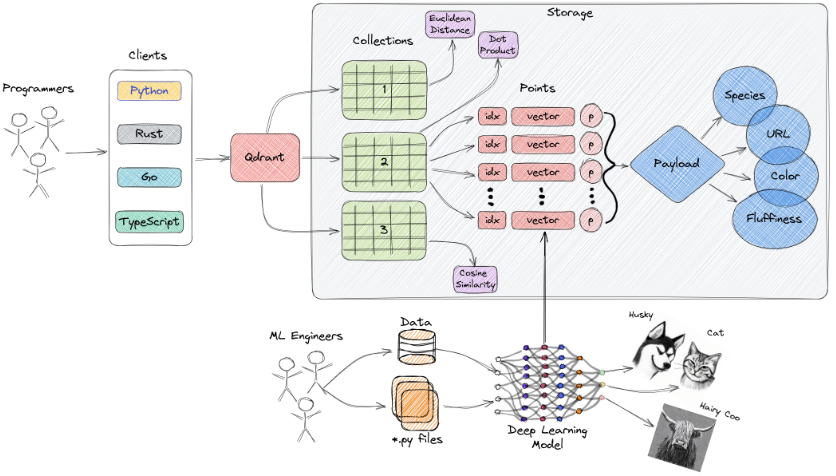
Qdrant의 핵심 아키텍처 구성 요소
Qdrant를 이해하려면 기본 구성 요소를 먼저 알아야 합니다. 아래는 주요 개념들입니다.
- Collection
벡터 데이터들을 저장하는 단위입니다. 같은 Collection 내의 벡터는 동일한 차원을 가지며 동일한 거리 측정 방식(metric)을 사용합니다. - Point
Qdrant의 핵심 단위로, 하나의 벡터와 그에 대한 고유 ID, 그리고 부가 정보를 담고 있는 payload로 구성됩니다. - Vector
문서, 이미지, 음성 등 데이터를 고차원 수치로 표현한 결과물입니다. - Payload
벡터와 함께 저장되는 JSON 형태의 추가 데이터입니다. 예를 들어 문서 제목, 카테고리, 작성자 등 메타 정보를 포함할 수 있습니다. - Distance Metric
벡터 간 유사도를 계산하는 방식입니다. Qdrant는 다음 세 가지 방식을 지원합니다.- Cosine Similarity: 방향 기준 유사도 측정 (값 범위: -1 ~ 1)
- Dot Product: 벡터 길이와 방향 모두 고려
- Euclidean Distance: 유클리드 거리 계산 방식 (거리 기반, 값이 작을수록 유사)
- Storage
- In-memory 저장: RAM을 활용해 속도가 빠름
- Memmap 저장: 디스크 기반 가상 메모리 방식
Qdrant의 주요 특징과 장점
Qdrant는 벡터 데이터베이스로서 다음과 같은 특징을 갖고 있습니다.
- 고차원 벡터 검색 최적화
HNSW(Hierarchical Navigable Small World) 기반의 인덱싱 구조를 통해 빠른 유사도 검색이 가능합니다. - Payload 기반 필터링 지원
단순한 거리 계산 이상의 조건 검색이 가능해 다양한 응용이 가능합니다. - 간단한 API 설계
REST API 및 gRPC를 통한 직관적인 인터페이스 제공. - 다양한 클라이언트 언어 지원
Python 외에도 다양한 언어에서 사용할 수 있도록 클라이언트 제공. - 실시간 검색 성능
수백만 개의 벡터 중에서도 빠른 검색 응답 속도 제공. - 오픈소스 및 클라우드 지원
온프레미스 및 클라우드 환경 모두에서 유연하게 운영 가능.
기존 데이터베이스가 구조화된 데이터를 처리하는 데 최적화되어 있다면, 벡터 데이터베이스는 비정형 데이터의 의미 기반 검색에 최적화되어 있습니다. 자연어 처리, 이미지 검색, 추천 시스템 등 현대적인 AI 응용 분야에서는 벡터 DB가 선택이 아닌 필수가 되어가고 있습니다.
Qdrant는 벡터 기반 검색을 간편하게 구현할 수 있도록 돕는 실전형 엔진으로, 빠른 속도와 다양한 필터 기능, 유연한 구조를 통해 실무에 즉시 적용할 수 있는 장점을 갖추고 있습니다.
이제 키워드가 아닌 의미를 검색하는 시대입니다. Qdrant는 그 흐름에 맞춰 진화하고 있으며, 이를 통해 더 정교하고 빠른 검색 경험을 사용자에게 제공할 수 있습니다. 새로운 검색 시스템 구축을 고민 중이라면, Qdrant는 반드시 고려해봐야 할 솔루션입니다.
https://qdrant.tech/documentation/overview/
What is Qdrant? - Qdrant
Qdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.
qdrant.tech
